This week the Perl Weekly Challenge task one was about calculating the Chinese Zodiac element and animal. I've solved it in Perl and Elm and share them here. Both I did in a TDD style; the Elm one benefits from my having solved in Perl first I think.
Perl
The Perl version I ended up with this test:
useTest2::V0 -target => 'Zodiac';
is $CLASS->sign_from_year(1938), 'Earth Tiger', '1938 -> Earth Tiger';
is $CLASS->sign_from_year(1967), 'Fire Goat', '1967 -> Fire Goat';
is $CLASS->sign_from_year(1973), 'Water Ox', '1973 -> Water Ox';
is $CLASS->sign_from_year(2003), 'Water Goat', '2003 -> Water Goat';
is $CLASS->sign_from_year(2017), 'Fire Rooster', '2017 -> Fire Rooster';
done_testing;
I find this a bit clunky, the code that generates the lookup table is a bit mystical and has some magic numbers. As you'll see in the Elm version, actually just having the lookup table as a simple array might be better for readability.
The sign_from_year is pretty simple I think, it "should" reference the formula from the wiki page really. I've left it pretty much as the formula describes... which I think in this case makes sense for a future developer looking at the code. It's not concise, but reflects the "business logic" and the language matches that of the language of the "domain". The wiki page author I hope would be able to see the steps they described in that function. So if I misunderstood the steps, hopefully they would see it without being a Perl developer.
Elm
The equivalent Elm test code looks like this:
module Zodiac_test exposing (..)
import Array
import Browser exposing (element)
import Expect exposing (Expectation)
import Fuzz exposing (Fuzzer, int, list, string)
import Html exposing (footer)
import Test exposing (..)
import Zodiac exposing (..)
sign_from_year_test =
describe "Zodiac sign_from_year"
[ test "1967 -> Fire Goat" <|
\_ ->
let
sign =
Zodiac.sign_from_year 1967in
Expect.equal sign "Fire Goat"
, test "2017 -> Fire Rooster" <|
\_ ->
let
sign =
Zodiac.sign_from_year 2017in
Expect.equal sign "Fire Rooster"
, test "1938 -> Earth Tiger" <|
\_ ->
let
sign =
Zodiac.sign_from_year 1938in
Expect.equal sign "Earth Tiger"
, test "1973 -> Water Ox" <|
\_ ->
let
sign =
Zodiac.sign_from_year 1973in
Expect.equal sign "Water Ox"
]
table_index_test =
describe "Zodiac table_index"
[ test "1967 -> 44" <|
\_ ->
letindex =
Zodiac.table_index 1967in
Expect.equal index44
, test "2017 -> 34" <|
\_ ->
letindex =
Zodiac.table_index 2017in
Expect.equal index34
, test "1973" <|
\_ ->
letindex =
Zodiac.table_index 1973in
Expect.equal index50
]
table_test =
describe "Zodiac table"
[ test "60 rows" <|
\_ ->
let
ztable =
Zodiac.table
in
Expect.equal (Array.length ztable) 60
, test "row 44 -> Fire Goat" <|
\_ ->
let
ztable =
Zodiac.table
element =
case Array.get 44 ztable ofJust foo ->
foo
Nothing ->
"Error!"in
Expect.equal element "Fire Goat"
, test "row 34 -> Fire Rooster" <|
\_ ->
let
ztable =
Zodiac.table
element =
case Array.get 34 ztable ofJust foo ->
foo
Nothing ->
"Error!"in
Expect.equal element "Fire Rooster"
]
You can see that I benefited from having written the Perl solution already, it is a good lesson to any of us. The second implementation of your solution is often better than your first as you learnt a few things doing the first one. Too often, once we do the first implementation we never do a second. Be that in another language like this; or a refactor in the same language.
I use a simple list, rather than the complicated looping I did in Perl. Which for me is more elegant, a new developer coming to my code I think will see the zodiac signs and understand it a lot more easily than the calculated version.
The other thing I do better in the Elm version is break the code into three components, and test them accordingly. With the Perl version I basically just did a "service" test or "integration" test. Though they are all "unit" tests.
The tests in Elm verbose. That may be the way I wrote them, it might be the library. In either case I don't mind. I like the test format, it's descriptive and the verbosity is balanced against specific and readable tests. I am not a fan of super complicated tests when I can't easily see the input, the command call and the expected value. I like that this test tells me what I am testing.
The table_test may seem a bit excessive when you compare it to the code it is testing. It is, the reason being that I had a different approach when I started (calculating the table) so I had tests to confirm I had the right number of elements. Trying to test and code it proved more difficult than it felt worth doing. So I simplified the code. I did not remove the tests as they kept passing when I changed approach.
Comparing the two implementations, I prefer the Elm one this time (unlike when I did this previously). I think the reason is that this time I started in a TDD style with the Elm, which meant that I broke it into easily testable units. Which helped with the design of the code.
I wish I had recorded my coding up the Elm implementation as the end result does not show the way the TDD approach and an exquisite compiler helped me to quickly take small steps towards the solution. Next time I shall try and be good and do that.
Thanks once again to Mohammad for running the challenge. Please chat with me about this via the @perlkiwi twitter handle.
Recently I discovered the way to tell GitHub to correctly identify Perl code as Perl when it thinks it is Raku/Perl6.
GitHub has a tool called "Linguist" that detects what languages are in your repository; unfortunately sometimes it gets things wrong. I have some Raku repositories and some Perl... but sometimes .pm and .t files get classified as Raku although being Perl.
So I did a bunch of googling and worked out that you can be explicit about what you want to show using a .gitattributes file. To this file I add:
*.pm linguist-language=Perl
*.t linguist-language=Perl
This was enough to help persuade GitHub to classify my code correctly. This change put my pure Perl code base to 100% Perl, which I think is a good thing for the language and people seeing the amount of Perl code online on GitHub.
Using the same process I was able to fix a Elm application, that I host via GitHub that reported as having JavaScript and HTML, where is fact it's all Elm. It's a trick you could use to stop vendor-ed code appearing in your language statistics. In my case I just added the following to the .gitattributes file:
*.html linguist-detectable=false
Which is because elm make creates an HTML file with JavaScript within it. So this prevents the repo looking like a mix of Elm, HTML and JavaScript when in actuality it is solely Elm.
Not a huge thing, but thought I'd post it so others might find it and be able help ensure Perl shows up correctly in the percentages.
I you head over to the https://perlweeklychallenge.org/blog/perl-weekly-challenge-100/#TASK2 page, you'll see the idea here. Calculate the smallest sum of the nodes in a triangle/tree of integers. This is a pretty classic problem and is solved a bunch of ways; my approach is the "Dynamic Programming" approach in Perl.
So the pseudo-code for this is:
Take the array of arrays and make it a table/matrix
Start at bottom row and calculate the smallest sum option.
Repeat moving up the rows
Return cell 0,0 which "should" be the minimum path sum.
As ever, I start with a test and work my way out from there. Adding the simplest solution I can as I go along... literally return static values at first. So I call a class method, see the tests fail. Then create the .pm file, name it and add a sub foo { return 8; } which literally does nothing. Then I expand out from there.
Lets break with tradition and lets look at the completed module first:
So you can see the I broke the problem up into two stages:
triangle_to_table
parse_table
Bad names I think, but it does mean that hopefully you can recognise the approach I described in pseudo-code. There are absolutely better ways of doing this, but this works and I know it works because of the tests I wrote as I explored the approach:
And the first iteration of Triangle.pm looked like this:
package Triangle;
sub min_path_sum {
return8;
}
1;
As I've said elsewhere, this is my style of doing things. Write a test, hard-code a return value. Then I know that I have the simplest solution. If Mohammad literally only had the one example, I'd stop there as I have met the "user requirement".
But there is more than one example, so a simple return does not suffice (of course) so I did implement the next stage. In my case, I actually moved forward by hard coding the triangle_to_table sub, and worked on the actual logic to solve for first example properly. THEN, I added the second example as a test and it failed as the triangle_to_table sub was stubbed out. So then I wrote tests for that sub and implemented the logic.
The nice thing here was that once I did that, the tests worked and adding the second example to the min_path_sum test just plain worked. :)
A good example of how TDD helps you design and then maintain integrity when you get it right. It took me a little longer (arguably) to get to a working solution... but it got faster as I went along and when I was "done" I had confidence I was finished as the tests confirmed it. At least in so much that the assumptions I tested were true. I have not coded for edge cases, etc.
I actually find TDD gives me a smoother ramp up, I start coding with super simple building blocks, the scaffolding which I need to build my solution. And line physical scaffolding, it's pretty easy to put together and when done shows the shape of things to come. I find it gets my head into the right space to do the "hard stuff". I have got the dopamine hits of tests passing, I've also very lightly started thinking through interfaces and the problem space.
I should also focus some attention on the pseudo-code stage of the process.
This you could call the High Level Design (HLD) as it's been called in places I have worked. This is the whiteboard scribbles, the napkin design that serves as the first feedback cycle in the design. As you can see from the example at the top of this page, my initial plan had four steps. By the time I finished you can see that was altered to be 2 methods. So my design changed even between the time I wrote the pseudo-code and when I started coding. That is super cheap, this is the essence of pragmatic software development for me. Do the smallest thing that gets me feedback that I know what I am doing will work. Then do the next step.
The final step (and I admit I often skip this) was to wire this into a Perl script someone could call from the command line. This was actually one that took me a little longer than it should, and I'd not want to ship my solution to a real user as it's definitely a kludge.
My script basically allowed me to cut and paste the Perl style arrayrefs that the challenge used directly. It meant some ugly regexing away the square brackets and using Perl's flexibility to auto-magically know that I wanted the strings that contained numbers should be integers to do the minimum_path_sum calculations to.
By this I mean that the way I wrote this the Perl script just sees an array of strings. So the square brackets are removing the character from the string. The split makes an array of strings from the row strings. Then pushes a reference to that array of strings into @triangle and returns that.
The min_path_sum method just starts treating the elements as integers later (in the comparisons and addition). It's one of Perl's strengths compared to typed languages for example where I'd have to explicitly do a conversion (if you look at my Elm solution to task 1 (previous post) you'll see I need to use String.toInt to make that happen. In Perl I don't have to do that dance. Yes, there are downsides and weird bugs that "could" occur; but for the purposes of this code, I don't need to worry about it and can just benefit from this feature of the language.
Summary
This was another fun one, nice to work on. The pattern is one we have seen in other challenges, and every time you get to exercise an approach intentionally it helps to cement it into your mind/toolkit. Making it easier to identify and take advantage of in a different context.
I hope if you have read this far that it was of interest and that you'll drop me a message with your thoughts.
This week marks the 100th edition of the Perl Weekly Challenge a fantastic project started back in March 2019. Since the start it has garnered a lot of support from Perl developers and other languages.
This week, so far; I have solved the first solution in two languages. Firstly Perl and secondly in Elm. I like both languages a lot and decided to coin the term pErLM to describe my use of Perl as my back-end language and Elm as my front-end language.
Perl is the mature, super stable, well proven technology that runs almost anywhere and is flexible and allows many ways of doing things. Great library support and "boring" in the good sense of the term. Perl just works for me.
Elm on the other hand is new, very constrained and serves one purpose... creating web applications.
The combination or Perl and Elm (pErLM) provides a fantastic combination. Elm provides the interactivity on the front-end and Perl the flexibility on the back end. Where Elm provides types and constraints to work within, Perl provides options for those "side effects". Using a web framework like Dancer2 makes scaffolding up a back-end for a Elm app a breeze.
Both language have a great formatter and static analysis... sort of. Perl has Perl::Critic and Elm has well it's amazing compiler.
I recommend giving it a try, let me know how you get on. I'll be posting about how I have started adopting this pErLM shape on the side project I have been renovating from CGI to PSGI/Dancer2 to a JSON back-end and Elm front-end.
But that's the future... today lets look at how I implemented the challenge for week 100 in both languages.
Challenge 100
This weeks challenge is a time converter. When given a time in 24 hour format; return it in 12 hour format and vice versa.
Perl version
So I did this challenge on my normal style; starting with a .t test file:
useTest2::V0 -target => "Fun";
is $CLASS->convert("05:15 pm"), '17:15', 'Example 1-1';
is $CLASS->convert("05:15pm"), '17:15', 'Example 1-2';
is $CLASS->convert("19:15"), '07:15pm', 'Example 2-1';
is $CLASS->convert("09:15"), '09:15am', '24hr AM';
done_testing;
Four simple tests (yes I did them one at a time in a TDD-esque style), the code I ended up with looks like this:
Nothing too clever to talk about here; this is a un-refined solution; but works and provably works.
I also created a small script file to meet the requirement to use this from the command line:
usestrict;
usewarnings;
use lib './lib';
use Fun;
my$fun = Fun->new;
print$fun->convert($ARGV[0]);
print "\n";
Short and to the point. I have a confession to make; Mohammad if you are reading this I saw the "Ideally we expect a one-liner." instruction... and ignored it completely! :-)
Why?
Because I don't have an interest in one-liners; it is partially as I am too lazy to put the work in and partially because I don't like to promote Perl in that context. Perl is a graceful language; but can also be a code golfers paradise. One liners and code golfing is, to use a common refrain, "considered harmful" for the Perl community I think broadly.
The main reason I say that is the external perspective of Perl, I read too many tweets and blog posts that when they talk about Perl it's not positive often because of the perception created by the "clever" Perl one-liner. To be clear, the clever one-liners are superbly powerful and useful in the right hands. But I feel that they should be what we discover later in our Perl journey and not be the think we place front and centre.
That's just a personal perspective. Give it some thought and tell me what you think.
Elm
My Elm solution is... ugly and incomplete. It's not a functional web app just a some code that does the conversion. I did the least effort possible, its not DRY, it's not thought through... you have been warned.
So again, I start with a test; the final version here (again I started with a single test):
module Example exposing (..)
import Expect exposing (Expectation)
import Fun exposing (convert)
import Fuzz exposing (Fuzzer, int, list, string)
import Test exposing (..)
suite : Test
suite =
describe "Fun" [ test "convert 07:15" <|
\_ ->
let
got =
convert "07:15"
in
Expect.equal got "07:15am"
, test "convert 05:15pm" <|
\_ ->
let
got =
convert "05:15 pm"
in
Expect.equal got "17:15"
, test "convert 19:15" <|
\_ ->
let
got =
convert "19:15"
in
Expect.equal got "07:15pm"
, test "convert 09:15" <|
\_ ->
let
got =
convert "09:15 am"
in
Expect.equal got "09:15" ]
And the (ugly... I have warned you) code looks like this:
module Fun exposing (convert)
convert : String -> String
convert time =
if String.contains "am" time then
String.slice 0 5 time
elseif String.contains "pm" time thenlet
hourMin =
String.split ":" time
incase List.head hourMin of
Just a ->
let
hour =
String.toInt a
in
case hour of
Just h ->
let
hx =
h + 12
in
String.fromInt hx ++ String.slice 2 5 time
Nothing ->
""
Nothing ->
""
else
let
hourMin =
String.split ":" time
in
case List.head hourMin of
Just a ->
let
hour =
String.toInt a
in
case hour of
Just h ->
if h > 12 then
let
hx =
h - 12
in
let
hourStr =
String.fromInt hx
in
if String.length hourStr > 1 then
hourStr ++ String.slice 2 5 time ++ "pm"
else
"0" ++ hourStr ++ String.slice 2 5 time ++ "pm"
else
String.slice 0 5 time ++ "am"
Nothing ->
""
Nothing ->
""
As you can see lots of ugly repetition and some naive approaches. I've not broken the code out into sub functions there is not typing etc. But it works and it provably works.
Thoughts?
As you can see neither solution wins any prizes for conciseness; but interestingly the Perl is tidier. This is partially because I naturally write better Perl that Elm at the moment. Especially "first pass" code like these two example. The other reason in my opinion is that Perl is well suited to the task and Elm less so.
Elm is designed to create a interactive web application, handling human interactions (via messages) and representing these changes in a web page. Being a functional language side effects are intentional discouraged and immutable data is what we want. It is ideal for interactivity, sending and receiving data from an API and that sort of thing.
Perl is really well suited to handling text, massaging it into something else and returning it. Even my simplistic implementation is smaller and makes more sense than the Elm equivalent. I think after some iterations and refactoring the Elm would be a lot tidier... but again it's pushing against the flow of what Elm wants to be.
So I like this as an example of why I like my new "pErLM" stack. Elm does one thing and does it well, front-end. Perl does not work here at all; but is ideal for a stable back-end. Where Perl is flexible and able to do a wide variety of tasks well; Elm is tightly constrained and does not make doing things other than a web front-end easy.
So doing this dual implementation is for me an example of using the right tool for the right job.
Next?
So after this, I want to do the challenge in another language. Clojure (Lisp) I think; a language I have never worked in. Maybe PHP (that's an easy one I know) or perhaps Node if time/energy permits. But those are easy choices; so I want to try this in a lisp as it's very different... what other languages do you think I could try?
This week I wanted to explore more alternative ways of approach a new code base; be it Perl or any other programming language.
Online tools
If you are using a tool like GitHub, you have some tools at your disposal already. In the earlier posts, the screen shots of code I shared were from GitHub, I just zoomed out in the browser. I find the Contributors info in "Insights" really useful. You can see who wrote much of the code, then look at the commits to get a feel for where the churn is.
As a Perl person, you might like to take a look at Kritika.io as an example of the value of good tools. It unlike many has strong Perl support, such as Perl::Critic (more on that shortly), along with giving school style "grades" on specific files (A, B , B-, etc). It also tells you about churn, complexity and lines of code.
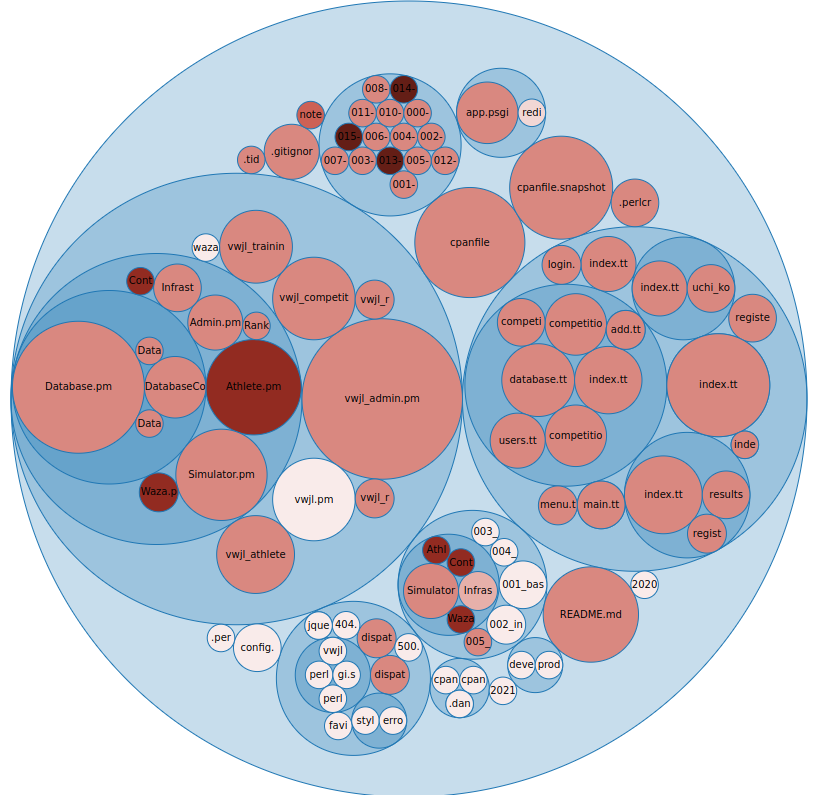
One of the interesting parts of Kritika (and similar tools) is the diagrammatic depictions of your code base, such as this one:
This gives a perspective on change "frequency over X time", in this case you can see the larger files have changed more frequently and the darker ones are more recently changed. This can give some insights into areas that are frequently changed (often problem areas) and so forth. A large frequently changed file for example might be one to consider breaking up.
Local tools
Kritika, is an interesting tool that prings us to Perl::Critic a staple of Perl development and a really great tool that is undervalued sometimes. It's incredibly extensible, so can do far more than what it does "out of the box". I'd strongly recommend running it on any new code base to help identify known "code smells".
Along with identifying code smells, it's very good at giving you some statistics on your code base, via the --statistics command, for example:
$ carton exec 'perlcritic --statistics-only lib'
19 files.
33 subroutines/methods.
1,153 statements.
1,670 lines, consisting of:
316 blank lines.
3 comment lines.
0 data lines.
1,351 lines of Perl code.
0 lines of POD.
Average McCabe score of subroutines was 2.33.
2 violations.
Violations per file was 0.105.
Violations per statement was 0.002.
Violations per line of code was 0.001.
2 severity 4 violations.
2 violations of Subroutines::RequireFinalReturn.
So in this (not terrible) example; we can see that the complexity score of subroutines is 2.33, we have some statistics there about violations per file, statements and lines of code.
We also can make some measures of subroutines to files rations etc.
Another interesting way of looking at your new code base is gource
In the video above, you can see how developers have worked on the code base and see hot-spots and trends.
Another interesting tool, that may help with a legacy Perl code base is Code::Statistics. Once installed, you can run with codestat collect which will collect statistics on your code base. After which you run codestat report which will give you something like this:
This is probably one of the key approaches, run the tests. Understand the tests.
Then write more tests.
No tech solution
Draw it; never underestimate the power of drawing a diagram that shows the connections between classes.
Start with whatever you find easiest (say the homepage if a web app), and work through all the connections. Mapping out perhaps what the data provide to the template is, what does that connect to? What methods are called? What data is passed around.
This might help you identify the code that is "business logic", what is "infrastructure" etc. Where are the linkages? What files have too much code in them? Is there a clear flow to the code?
Visualising it can be super powerful, even if like me you are not particularly artistic.