Recently I was invited to give a tech talk at the Southampton Perl Mongers group online event. It was great to spend some time with local and not so local (Hello to our new friends in Texas!) Perl users.
The talk was an abbreviated version of the talk I had planned to give at the German Perl Workshop 2021 but was unable to do. In this post I want to share the content and some bonus content not included that I should have included probably.
Here is the video of the talk I made after the event:
Overview
The talk was some experiences I've had mainly renovating an old Perl CGI app, I wrote in the late 1990s and early 2000's which was parked gathering dust till Christmas time 2020.
The 3 steps I describes were:
* Get it working
* Tidy up
* Modernise
Followed by some learnings and some advice.
Get it working
This seems obvious, but made a big difference for me. Mixing making it work and improvements is a mistake I think. It's tempting but just getting it to work will more than likely force changes in the code. Couple those changes with tidying up and you are more likely to break things.
One of the big challenges I found was the (re)learning of how the code works. What ideas and approaches were in use at the time. Just "getting it working" provides opportunity to learn the general shape of the code and what it depends on to work. Be that old CPAN modules, environment variable, files on disk or databases (and specific database versions).
You will have to change code even if you are just trying to get a working local version.
Getting it working TWICE is super valuable too. So both a local dev setup and a fresh server somewhere. This doing it twice helps find things that are not obvious. For me the differences from a local ArchLinux machine and a Ubuntu Server helped me identify differences.
In the talk and afterwards in the discussion, the idea of writing down what you learn as you go along was covered. This is skill and habit well worth developing if you are working on legacy code... or new code in fact. I kept notes on blog articles I read and followed. I scribbled notes on how to start/stop things. I absolutely had moments where I did something on Friday and come Monday had forgotten what I had done, why or how I came to the information I used to influence what I tried. WRITE IT DOWN... it's worth it!
Plack::App::CGIBin
Specifically for me, I was working with an old set of .cgi files. There were previously running on a server under Apache. Locally, I did not have; nor want that overhead. So I needed a tool called Plack::App::CGIBin which allows you to simply point it at a directory of .cgi files and serve it as a plack app via plackup. This was essential for my local development setup so I could see the working app once again.
At this stage the home page loaded nicely but not a lot else as CPAN modules were not on my system.
Carton and cpanfile
Managing the dependencies the app had was important (especially with an older application, where breaking changes can often appear). My choice here is to use the tool carton which reads a cpanfile and installs the CPAN modules locally (into a directory called local in the working directory). Then you can run with these specific CPAN modules using carton exec.
When I was trying to get the application up and running, I had some issues and it was really helpful to have two copies of the source code in different directories and be able to use carton to run different versions of the same CPAN modules. This helped me identify breaking changes. Not having to rely (or mess with) system wide CPAN modules was/is really valuable.
Hard coding and deleting
As I got to understand the code better when getting it working; it became clear that some things were not worth retaining. So the delete key was a really effective method to get the application working. The other trick that I used was to simplify the problem by hard coding some variable that were originally designed to more flexible but generated complexity.
Deleting code and hard coding things helped get the app to the state that it "worked" again. It was not 100% functionality restored; that in itself was a great learning experience. It's easy to think that all the features the legacy code had in place matter and/or worked.
Tidy up
Once the application was working, the next phase was to tidy the code in advance of planned modernisation.
I feel it's valuable to separate the tidy up from the modernisation. I find and found that the act of tidying up involves some modernisation anyway. What I mean here is that knew at this stage that I wanted to replace the data handling part of the code; but decided that I wanted to tidy up first as I knew that it would involve some changes to the code AND some collateral modernisation. If I tried to modernise during or while cleaning up I think it makes the task more difficult.
Perltidy
I suspect most Perl developers have used Perltidy and are familiar with the way it formats the source code in a consistent manner. When picking up a legacy code base it's really helpful to find a moment to perltidy everything. This will make the existing code look more familiar (especially for those of use using Perltidy a lot and are used to the style choices). I tend not to customise the perltidy setting too much leaving it pretty much on defaults.
Perlcritic
Another well used tool, perlcritic allows you to automate some stylistic decisions that are regarded and "Best Practices". Specifically, "Perl Best Practices" the book standards. I am not saying that all the PBP standards are ones I follow but I appreciate the standardisation it offers. It is a wonderful tool to help shape legacy codebase. It did help me identify some common things to improve (double to triple arg file opens for example).
WebService::SQLFormat
SQL is a language in itself, so like the Perl I think it's valuable to have some consistent formatting of the SQL in the app. I didn't use a ORM when the app was first written and broadly find the benefits of writing SQL outweigh the benefits of an ORM... your mileage may vary.
I started out using a website and copy and pasting SQL back and forward. Later I identified the WebService::SQLFormat module and was able to write a small script that would format my SQL in a more automated fashion.
As with Perltidy I don't necessarily agree/like all the formatting choices it makes. But I value the consistency and ease to automate more than my aesthetic preferences.
Human Eye
A trick I applied to this code is the simple trick of zooming out my editor so that the code is tiny and I can see the "shape" of the code.
It's a remarkably effective way of "seeing" code smells. The easiest to describe is complexity added by layers of loops or if statements. You can easily see multiple levels of indentation and see that something there is complex. This is helped by having previously having run Perltidy; so do that first.
You also see large/long subs and are able to see dense code.
Zooming in on the areas that from "30,000 feet" look wrong, you can make quick gains by tackling these areas, then zooming back out to find what else looks problematic.
I did use some other tools to help with this, like trying to see cyclomatic complexity or file size. Frankly though helpful, the human eye and mind is exceptionally good at seeing patterns and I got more benefit from this trick than the tools.
Modernise
Having tidied up the code I was in a position to modernise. Starting with introducing Dancer2 as my web framework (Mojo/Catalyst might have been your choice... I went with Dancer2 as it's a tool I know well).
Having created the basics, the next stage was a cut and paste exercise of moving code out of CGIs and into routes. I was fortunate that I had used HTML templates originally so was saved the pain of breaking the HTML out of the code... many of use have been there and it's not fun.
Database change
The original code used a module called DBD::Anydata which was (it's deprecated now) handy at the time. I used it to read and write from CSV files using SQL statements. Yes really. It was a mad decision to use CSV files as the data store for the app; but in terms of modernisation it was fortunate as it meant that I'd not had written code to read/write data to files. I had written SQL inserts and selects, which meant that it was comparatively easy to migrate the app to Postgres.
I did need to write the schema creation etc.
Database Migrations
The schema was "OK" but not perfect and as I tidied more and had to make more changes I became annoyed with destroying and recreating the database each time. I explored using migration tools like sqitch XXX, but ended up quickly writing a migration tool in the admin area of the app that applied SQL statements in numerical order from a directory of .sql files. (With a migration level being stored in the database to prevent re-applying the same changes. Not sophisticated... but it works and was simplest solution at the time.
Docker
Initially I had a local installation of Postgres, but I work from multiple machines and quickly moved to using a dockerised installation of Postgres to simplify my development cycles.
Following this I added a Perl container to run the app itself.
Learnings
In preparing and giving the talk I was struck by how much of what mattered to me was not "technical" but "human" parts.
Write it down
This ended up being more important pretty much anything else. Having notes on what I was doing and why proved important when I took breaks from the code and came back to it. When I did poorly I would come back and not recall what specific things I was trying to do and why. This was really prevalent in the Postgres changes. I am not a docker guru and followed several guides; at least once I came back the next day and got lost as I did not take notes on what article I had read and what it taught me.
Automate it
Perltidy, Perlcritic, etc. The more I was able to automate the easier it became to use the tools and to remain consistent. This is true also of deploying the code. A "pipeline" be it Github actions or bash script makes life so much easier and the easier the process the better. My mind could stay of the code and the problems not on how did I get this deployed etc. So take those moments to automate things.
Do the simple things first
It's tempting to get stuck in and tackle hard problems at the start. I think this is a mistake. By starting with small simple things you gain familiarity with the code and the "domain". You discover the hidden complexity before you get deep into hard problems. This way when you get into the hard problems, your familiarity is high and you've discovered many of the complexities already. So do those simple things; it's why we often give the new member to a development team the simple update the template typo ticket right. Simple tasks mean you run through all the steps sooner and resolve the things that are not obvious.
Legacy code is a great place
There is enjoyment to be had in an older code base. Unlike a writing from new, a legacy code base is nuanced. You often have multiple ideas spanning the code base. As a developer touching legacy code you have the opportunity to discover how it was built, how it was changed, and why. This is satisfying work; learning how to code in the "old" style can be fun. Also moving a code from old to new can be satisfying. Finding the multiple styles of a code base and bringing them into alignment is a skill in itself and one that deserves more highlighting.
Legacy code, has made many decisions already. So often that "paralysis by analysis" problem is avoided as you are stepping into a situation where decisions have already been made. Another skill is understanding the constraints and mindsets that ended up in the code looking as it does. The old adage that the people who wrote were doing the best they could given the situation is valuable to keep in mind.
Legacy code is important, it exists and did something. New code is a gamble in a way. It's not proven, it's not been used. So Legacy code and maintaining it is a vital part of our industry and we need more people to value it.
- Perl's Legacy
Working in multiple languages, it's interesting to see the influence it has had on newer languages.
For example, Go has great testing tools out of the box and formatting. JavaScript's NPM is CPAN. PHP is getting better and has better tooling than it once did. Raku oddly given it's lineage does not have great tooling. There is no Rakucritic or Rakutidy. Go in many ways shows more influence of legacy Perl. Go is arguably built with Legacy in mind. It's intentionally constrained and comes with tools to help the legacy code age well.
Summary
I'll try and record myself giving the talk and share it on the site till then, thanks for reading along.
This is part three of an exploration of some ideas around how I approach picking up a legacy Perl codebase.
In part one I wrote about starting with tests and using carton to manage the module dependencies. In part two we covered Perl::Critic and looking at the code from that 30,000 view.
In this post; I'll show some of the refactorings that came from the 30,000 view.
So if you look at the code, you can see lots of repetition, which we can simplify.
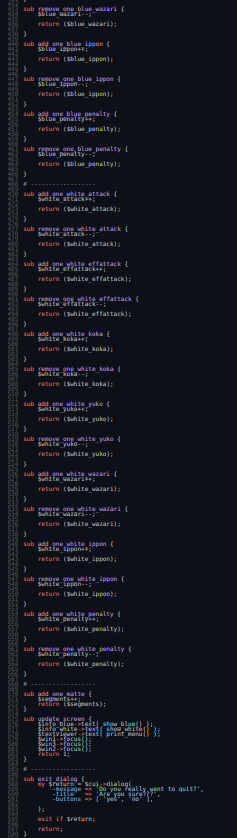
There are many repetitions that look like this:
sub add_one_white_penalty {
$white_penalty++;
return ($white_penalty);
}
sub remove_one_white_penalty {
$white_penalty--;
return ($white_penalty);
}
So what we can do is create a single sub that accepts some parameters and update the counters, so something like this:
sub update {
my (%args) = @_;
if ( $args{'mode'} eq 'inc' ) {
$counters{ $args{'colour'} }{ $args{'statistic'} }++;
}
else {
$counters{ $args{'colour'} }{ $args{'statistic'} }--;
}
}
So this single function can replace all those repetitions (we did also need to created hash to hold the data, rather than the many scalars.
The other large bit of repetition is the binding of keys to the update function, which before refactoring looks like this:
$cui->set_binding( sub { add_one_blue_attack(); update_screen(); }, 'f' );
$cui->set_binding( sub { remove_one_blue_attack(); update_screen(); }, 'F' );
$cui->set_binding( sub { add_one_blue_effattack(); update_screen(); }, 'd' );
$cui->set_binding( sub { remove_one_blue_effattack(); update_screen(); }, 'D' );
So we can reduce the repetition like this:
my @keys = (
[ 'blue', 'attack', 'inc', 'f' ],
[ 'blue', 'attack', 'dec', 'F' ],
[ 'blue', 'effattack', 'inc', 'd' ],
[ 'blue', 'effattack', 'dec', 'D' ],
[ 'blue', 'koka', 'inc', 'v' ],
[ 'blue', 'koka', 'dec', 'V' ],
[ 'blue', 'yuko', 'inc', 'c' ],
[ 'blue', 'yuko', 'dec', 'C' ],
[ 'blue', 'wazari', 'inc', 'x' ],
[ 'blue', 'wazari', 'dec', 'X' ],
[ 'blue', 'ippon', 'inc', 'z' ],
[ 'blue', 'ippon', 'dec', 'Z' ],
[ 'blue', 'penalty', 'inc', 't' ],
[ 'blue', 'penalty', 'dec', 'T' ],
[ 'white', 'attack', 'inc', 'j' ],
[ 'white', 'attack', 'dec', 'J' ],
[ 'white', 'effattack', 'inc', 'k' ],
[ 'white', 'effattack', 'dec', 'K' ],
[ 'white', 'koka', 'inc', 'n' ],
[ 'white', 'koka', 'dec', 'N' ],
[ 'white', 'yuko', 'inc', 'm' ],
[ 'white', 'yuko', 'dec', 'M' ],
[ 'white', 'wazari', 'inc', ',' ],
[ 'white', 'wazari', 'dec', '<' ],
[ 'white', 'ippon', 'inc', '.' ],
[ 'white', 'ippon', 'dec', '>' ],
[ 'white', 'penalty', 'inc', 'u' ],
[ 'white', 'penalty', 'dec', 'U' ],
);
for my $k (@keys) {
$cui->set_binding(
sub {
update(
colour => $k->[0],
statistic => $k->[1],
mode => $k->[2],
),
update_screen();
},
$k->[3]
);
}
This drops the line count from 440 down to 334 lines, smaller is better. Less code is less places for bugs to hide. The code is technically a little more complex, but simpler in that we are not repeating ourselves as much. So we can reduce the chances of introducing bugs.
When we zoom out on the code now, there code has a very different shape to it, the repetitive subs are no longer there. This helps highlight the next level of complexity, the display code... and that's what we will tackle next time.
This is part two of an exploration of some ideas around how I approach picking up a legacy Perl code base.
In part one I wrote about starting with tests and using carton to manage the module dependencies.
In this post; we will take a look at the code base itself and some ideas on how to quickly identity areas to improve.
Perl::Critic
Perl is a mature language, with mature tooling. One of the "hidden gems" of Perl is Perl::Critic, which is a static analysis tool that gives great insights into the code. One really powerful aspect is that we have a book to reference; "Perl Best Practices" and Perl::Critic can help us follow this guidance and will reference exact parts of the book. It's extensible and there are plenty of opinionated Perl developers who have shared their policies.
So lets run it and see what happens, after first adding Perl::Critic to the cpanfile.
$ carton exec perlcritic -5 Notator.pl
Notator.pl source OK
So at the least strict level, the file is OK. This is a good sign; nothing terrible wrong. So lets try another level of strictness:
$ carton exec perlcritic -4 Notator.pl
Magic variable "$OUTPUT_AUTOFLUSH" should be assigned as "local" at line 12, column 19. See pages 81,82 of PBP. (Severity: 4)
Subroutine "new" called using indirect syntax at line 87, column 12. See page 349 of PBP. (Severity: 4)
Subroutine "new" called using indirect syntax at line 355, column 20. See page 349 of PBP. (Severity: 4)
This time we get three lines, you can see the references to pages in the Perl Best Practices (PBP) pages that relate. There are also references to the lines in the file itself. So the last two lines are the same and are pretty easy fixes; so lets go fix those.
$cui = new Curses::UI( -color_support => 1 );
We can rewrite this as:
$cui = Curses::UI->new( -color_support => 1 );
That warning about the Magic variable is pretty self explanatory, so we can pop local at the start of the line as suggested.
If we re-run perlcritic we are now all clear again.
But if we look at the $cui = new Curses::UI( -color_support => 1 ); line, you'll notice that there is no my; which if we look about the file a bit gives us a clue... this file is all global variables which is generally a bad thing. Looking further the variables are at least tidy and sensible, but there are a lot of scalar variables which is not ideal. A to be fair to the 2007 author (which yes was me), they did leave a large comment to make it clear the variables are global.
my $run_flag = 1;
my $segments = 0;
my $active = 0;
my $events = 0;
my $blue_attack = 0;
my $blue_effattack = 0;
my $blue_koka = 0;
my $blue_yuko = 0;
my $blue_wazari = 0;
my $blue_ippon = 0;
my $blue_penalty = 0;
my $white_attack = 0;
my $white_effattack = 0;
my $white_koka = 0;
my $white_yuko = 0;
my $white_wazari = 0;
my $white_ippon = 0;
my $white_penalty = 0;
my $cui;
my $win1;
my $win2;
my $win3;
my $info_blue;
my $info_white;
my $textviewer;
Readonly my $BASEYEAR => 1900;
We can look at perhaps creating a hash so we decrease the variables... but that is minor. We could look at scoping the variables and so forth too. That use of Readonly we could alter too, does it really need to be readonly? Could we use constant instead?
But first lets look more broadly.
Getting the big picture
A tip for looking at a new code base is to literally scroll out and look at the shape of the code. This is an old hackers trick, but somewhere I have read research where teaching developers about code smells by looking at files at this zoom level was proven to be effective (as effective) as teaching the underlying principles.
So lets take a look:
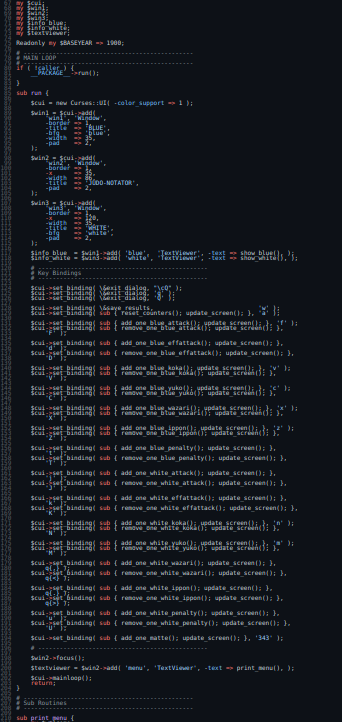
And...

What is leaping out to me lots of repetition, and the more code we write, the more bugs we introduce. So that looks like a really good place to invest some time and energy. So lets see what we can do there.
Looking at the second pic those look like a series of subroutines that have near identical structures, here are a few of them:
sub remove_one_white_effattack {
$white_effattack--;
return ($white_effattack);
}
sub add_one_white_koka {
$white_koka++;
return ($white_koka);
}
sub remove_one_white_koka {
$white_koka--;
return ($white_koka);
}
So yes they are all really similar; basically just altering those global variables; and looking at the other block of repetition we see:
$cui->set_binding( sub { add_one_white_effattack(); update_screen(); },
'k' );
$cui->set_binding( sub { remove_one_white_effattack(); update_screen(); },
'K' );
$cui->set_binding( sub { add_one_white_koka(); update_screen(); }, 'n' );
$cui->set_binding( sub { remove_one_white_koka(); update_screen(); },
'N' );
So this gives us some ideas on where we can focus our attentions, and that shall be the topic of the next post in this series.
Today I want to cover a little about how I go about resurrecting an old Perl code base. In this example I am working with an old ncurses application I wrote in 2009 as part of a Judo research project I was involved in at the time.
The following steps are perhaps of interest to anyone picking up a similar project from long ago... or adopting a new code base.
So I shall be looking at my Judo-Notator project.
Start with the tests.
If you are lucky, there should be a t directory in any perl project you pick up. Perl has a strong test culture, one of the really valuable parts of Perl is CPANTS. CPANTS is a free service that tests every Perl module in the CPAN. So you can expect with relatively high likelihood some tests in most Perl projects.
Within the Judo-Notator code base, there was a t directory holding three files:
- notator.t
- use_strict.t
- use_warnings.t
Interestingly, those second two files are just testing if all the Perl files in the project are using use strict and use warnings. That's "best practice", maybe I'd caught myself being lazy and wrote tests to stop me not adding those two pragma... but not really useful.
notator.t is more interesting, at only 41 lines it's clearly not comprehensive; but a quick look gave some clues to the code base structure.
At this point I tried the tests.
Unfortunately none of the tests work as there are some missing modules, specifically Test::Output and File::Find::Rule so now is a good time to start handling the module dependencies via Carton and a cpanfile. This code base does not have one; so I added one with the following:
requires "File::Find::Rule" => "0.34";
requires "Test::Output" => "1.031";
The cpanfile is used via the carton command line tool, which will read this file and install the modules in a local directory. So lets run carton install and then see what happens when we run the tests. This time we need to run prove with carton carton exec prove -l t.
This failed hard! Lots of errors; why? Because using carton created that local directory, and there are lots of perl modules in there that apparently don't use strict so at this point I needed to alter the test to only look in the root directory and not the children... or scrap them.
This is a tough call, it seems like a useless test... but the original author (which is younger me) might have written that test for a good reason. So I am choosing to make the test work, just in case. When working with a legacy code base; I think we need to assume if a test was written it was probably written for a good reason. So till know the code base we need to be careful about assuming something is not needed.
So after making the File::Find::Rule module stay in the first directory this is what the tests show us (you'll need to scroll right, my layout is too narrow and no word wrap...sorry):
$ carton exec "prove -lv t"
t/notator.t ....... Can't locate notator.pl in @INC (@INC contains: /home/lancew/dev/judo-notator/lib /home/lancew/dev/judo-notator/local/lib/perl5/5.31.11/aarch64-linux /home/lancew/dev/judo-notator/local/lib/perl5/5.31.11 /home/lancew/dev/judo-notator/local/lib/perl5/aarch64-linux /home/lancew/dev/judo-notator/local/lib/perl5 /home/lancew/perl5/perlbrew/perls/perl-5.31.11/lib/site_perl/5.31.11/aarch64-linux /home/lancew/perl5/perlbrew/perls/perl-5.31.11/lib/site_perl/5.31.11 /home/lancew/perl5/perlbrew/perls/perl-5.31.11/lib/5.31.11/aarch64-linux /home/lancew/perl5/perlbrew/perls/perl-5.31.11/lib/5.31.11) at t/notator.t line 9.
1..0
skipped: (no reason given)
t/use_strict.t ....
ok 1 - notator.pl uses strict
ok 2 - Notator.pl uses strict
ok 3 - smoketest.pl uses strict
ok 4 - guitest.pl uses strict
1..4
ok
t/use_warnings.t ..
ok 1 - notator.pl uses warnings
ok 2 - Notator.pl uses warnings
ok 3 - smoketest.pl uses warnings
ok 4 - guitest.pl uses warnings
1..4
ok
Test Summary Report
-------------------
t/notator.t (Wstat: 512 Tests: 0 Failed: 0)
Non-zero exit status: 2
Files=3, Tests=8, 1 wallclock secs ( 0.06 usr 0.01 sys + 0.46 cusr 0.05 csys = 0.58 CPU)
Result: FAIL
So 2/3 of the test files are working; so lets look at that last one. The test output is saying Can't locate notator.pl so lets look at the test file and see how it is structored:
#!/usr/bin/perl
use strict;
use warnings;
use Test::More qw(no_plan);
use Test::Output;
require 'notator.pl';
is( Local::Notator::dumb_test(), 'yes', 'dumb_test is OK');
like( Local::Notator::print_menu(), qr/ENTER = MATTE/, 'print_menu is OK' );
is( Local::Notator::reset_counters(), 1, 'reset_counters is OK');
like( Local::Notator::print_results(), qr/Segments/, 'print_results is OK' );
like( Local::Notator::show_blue(), qr/Penalty: 0/, 'show_blue is OK' );
like( Local::Notator::show_white(), qr/Penalty: 0/, 'show_white is OK' );
is( Local::Notator::add_one_blue_attack(), 1, 'add_one_blue_attack is OK');
is( Local::Notator::add_one_blue_effattack(), 1, 'add_one_blue_effattack is OK');
is( Local::Notator::add_one_blue_koka(), 1, 'add_one_blue_koka is OK');
is( Local::Notator::add_one_blue_yuko(), 1, 'add_one_blue_yuko is OK');
is( Local::Notator::add_one_blue_wazari(), 1, 'add_one_blue_wazari is OK');
is( Local::Notator::add_one_blue_ippon(), 1, 'add_one_blue_ippon is OK');
is( Local::Notator::add_one_white_attack(), 1, 'add_one_white_attack is OK');
is( Local::Notator::add_one_white_effattack(), 1, 'add_one_white_effattack is OK');
is( Local::Notator::add_one_white_koka(), 1, 'add_one_white_koka is OK');
is( Local::Notator::add_one_white_yuko(), 1, 'add_one_white_yuko is OK');
is( Local::Notator::add_one_white_wazari(), 1, 'add_one_white_wazari is OK');
is( Local::Notator::add_one_white_ippon(), 1, 'add_one_white_ippon is OK');
is( Local::Notator::add_one_matte(), 2, 'add_one_matte is OK');
like( Local::Notator::results(), qr/Penalty:/, 'results is OK' );
Line 9 is where the error occurs, it's a simple line:
require 'notator.pl';
This looks like a simple fix:
require './notator.pl';
This gives us this:
$carton exec "prove -lv t/notator.t"
t/notator.t .. Can't locate Curses/UI.pm in @INC (you may need to install the Curses::UI module) (@INC contains: /home/lancew/dev/judo-notator/lib /home/lancew/dev/judo-notator/local/lib/perl5/5.31.11/aarch64-linux /home/lancew/dev/judo-notator/local/lib/perl5/5.31.11 /home/lancew/dev/judo-notator/local/lib/perl5/aarch64-linux /home/lancew/dev/judo-notator/local/lib/perl5 /home/lancew/perl5/perlbrew/perls/perl-5.31.11/lib/site_perl/5.31.11/aarch64-linux /home/lancew/perl5/perlbrew/perls/perl-5.31.11/lib/site_perl/5.31.11 /home/lancew/perl5/perlbrew/perls/perl-5.31.11/lib/5.31.11/aarch64-linux /home/lancew/perl5/perlbrew/perls/perl-5.31.11/lib/5.31.11) at ./notator.pl line 8.
BEGIN failed--compilation aborted at ./notator.pl line 8.
Compilation failed in require at t/notator.t line 9.
1..0
skipped: (no reason given)
Test Summary Report
-------------------
t/notator.t (Wstat: 512 Tests: 0 Failed: 0)
Non-zero exit status: 2
Files=1, Tests=0, 0 wallclock secs ( 0.05 usr 0.01 sys + 0.16 cusr 0.01 csys = 0.23 CPU)
Result: FAIL
So we are missing another module, so time to update the cpanfile, run carton install and re-run the tests:
requires "File::Find::Rule" => "0.34";
requires "Test::Output" => "1.031";
requires "Curses::UI" => "0.9609";
requires "Readonly" => "2.05";
Which gives us this:
$ carton exec "prove -l t/"
t/notator.t ....... ok
t/use_strict.t .... ok
t/use_warnings.t .. ok
All tests successful.
Files=3, Tests=28, 1 wallclock secs ( 0.07 usr 0.00 sys + 0.67 cusr 0.05 csys = 0.79 CPU)
Result: PASS
At this stage I was able to try the notator.pl script via carton exec perl notator.pl... and it worked... at least it loads and the ncurses interface came up.
Perltidy time
It's really helpful to have a tidy code base before you dig deep into it. I also find that one big tidy is often justifiable. So I add the Perl::Tidy module to the cpanfile then run it against the Perl files. But before I do I want to add a .perltidyrc file to give me the default behavior I am used to:
--backup-and-modify-in-place
--backup-file-extension=/
--perl-best-practices
--nostandard-output
--no-blanks-before-comments
The useful ones here is that I modify the actual files; no .tdy files for me please.
The next step for me is a good read of the code; and determine what looks bad. I shall cover that in another post.
This is the first of a series of posts I want to write about some of the Perl projects I have written or am writing.
Introduction
Today I want to introduce ijf_ical; which is a Perl script to produce a iCal file of all the Judo events on the International Judo Federation (IJF) calendar. This allows me to subscribe to the file and have all the IJF events in my calendar. The data is sourced from the IJF's data so is kept accurate as event dates change.
Overview
The code is a messy 104 lines ( https://github.com/lancew/ijf_ical/blob/master/ijf_ical.pl ), which does the following:
- Get the JSON competition information from the IJF
- Create an iCal event for each competition
- Geocode the competition city and country and add the Lat/Long to the iCal event
- Print the complete list
Details
I use Carton to manage the module dependencies. Specifically for this project I use:
The code itself is pretty simple; it makes a GET request to get all the events in JSON format
It then loops around each competition creating an iCal event from the data, a call is made to the OpenStreetMap Nominatim API via Geo::Coder::OSM and the latitude and longitude added to the event.
Then the iCal event is pushed into an array
Once all the events have been looped through; it prints out the ical file.
Use
Running the script is as simple as carton exec perl ijf_ical.pl > ijf.ics. I run this locally in the repo and actually commit the ijf.ics file to the repo. This means I can subscribe to https://raw.githubusercontent.com/lancew/ijf_ical/master/ijf.ics in my calendar app and I have all the IJF Judo competitions on my phone/computer.
Todo
Ahem... some tests would be good; and automating the build and running daily/weekly perhaps?